How I used Claude Code to land a B2B consulting client
138 cold messages. 11 Looms. 1 client. The exact scripts, research prompts, and message templates — all of it.
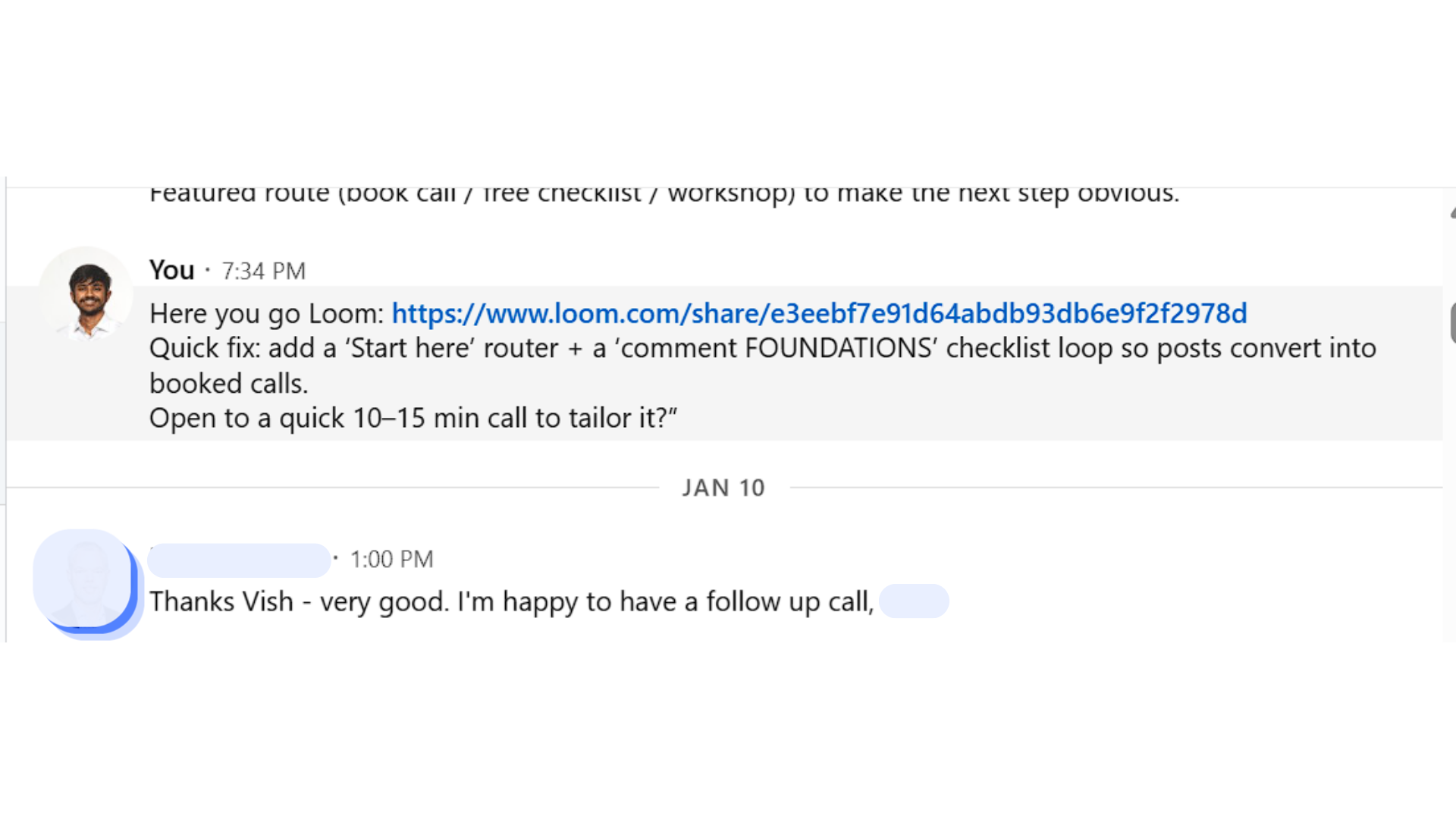
Loom sent after a research-first cold message. They replied the next day.
Six files. One working system.
Not a PDF of advice. The actual Claude Code project — directive file, execution scripts, and prompts — so you can run the same workflow on your own leads in an afternoon.
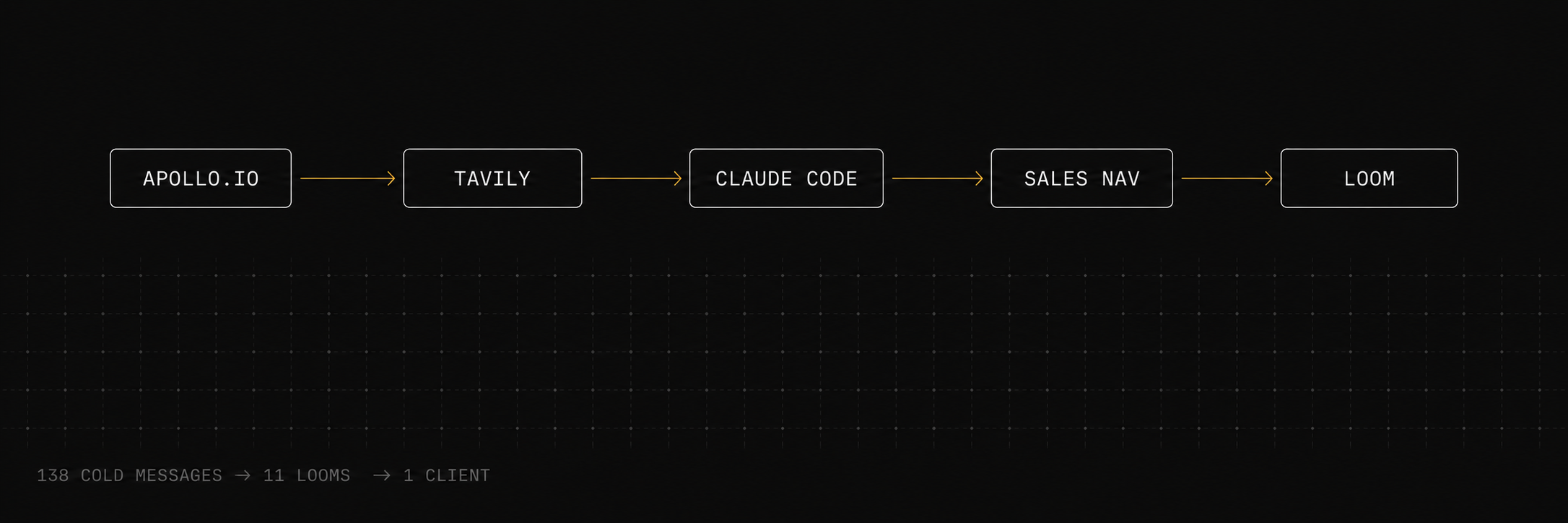
Five steps. No spray and pray.
Most cold outreach fails before it’s sent. You pull a list, write a template, swap in the first name. It reads like exactly that — and your reply rate shows it. This system inverts the order: research first, write second. Claude doesn’t write the emails. Claude orchestrates.
The filter set that matters isn’t job title — it’s company motion. Headcount 10–50, seed to Series A, recent funding, relevant industry vertical. Companies in motion respond. Static lists don’t. The script exports a clean CSV with the columns Tavily needs downstream: company name, homepage URL, LinkedIn URL, contact name.
Before Claude writes anything, Tavily scrapes: homepage, press mentions from the last 90 days, and any recent product or funding news. The raw results land in a single JSON file — no per-company files, no wasted credits. That JSON is what Claude reads when it writes the message. This is the step most people skip, and the one that does all the work.
The message template enforces two rules: reference something you couldn’t know from their homepage alone, and lead with what you’d change about their funnel — not what you offer. Claude enforces both. The result reads like you spent 20 minutes researching each company. You did. Your system did it for you.

When replies come in, Claude reads them: positive signal, objection, or noise. Positive signals get flagged for a same-day Loom. Objections get a short templated response. Noise gets archived. You only deal with the ones worth your time — which ends up being about 3–5% of total replies, but they’re all real.
90 seconds. Screen share of their actual product or funnel. One specific thing you’d fix, with a reason. Direct ask at the end — that’s it. 11 of 138 warranted a Loom. 1 of 11 converted. A 9% close rate on qualified follow-ups isn’t magic — it’s what happens when you only send Looms to genuine signals, and when the Loom references work you actually did.
The project lives in Claude Code’s agentic environment. One directive file tells Claude what to do. Python scripts do the deterministic work. .tmp/ holds intermediates that get regenerated each run — you never commit them.
.antigravity/Outreach/ ├── directives/ │ └── outreach.md ← the SOP Claude reads each session ├── execution/ │ ├── main.py ← runs the full pipeline end-to-end │ ├── url_finder.py ← finds company homepage via Tavily │ ├── scraper.py ← scrapes and cleans homepage content │ ├── research.py ← Claude extracts the outreach angle │ ├── write_messages.py ← Claude drafts from the research brief │ └── qualify_replies.py ← routes replies by signal strength ├── output/ │ ├── leads.csv ← Apollo export (your input) │ └── messages.csv ← personalised messages, ready to send └── loom_template.md ← the 90-second follow-up format

Get the exact files — free with your email.
Setup takes an afternoon. Runs entirely in Claude Code. Bring your own Apollo and Tavily API keys — both have free tiers that cover a first run.
This system runs on Claude Code
This isn’t a Claude chatbot workflow. It’s a 3-layer system built in Claude Code’s agentic environment. Claude reads the directive file, calls the Python scripts in order, handles errors, and updates the directive when it learns something. The deterministic parts — API calls, CSV parsing, file operations — are Python. The decisions are Claude. That separation is why it doesn’t compound errors the way pure-LLM pipelines do.